Publications
Hansheng Chen, Bokui Shen, Yulin Liu, Ruoxi Shi, Linqi Zhou, Connor Z. Lin, Jiayuan Gu,
Hao Su, Gordon Wetzstein, Leonidas Guibas
arXiv, 2024
3D-Adapter enables high-quality 3D generation using a 3D feedback module attached to a base image diffusion model for enhanced geometry consistency.

Hansheng Chen, Ruoxi Shi, Yulin Liu, Bokui Shen, Jiayuan Gu, Gordon Wetzstein, Hao Su,
Leonidas Guibas
arXiv, 2024
MVEdit is a training-free 3D-Adapter that enables 3D generation/editing using off-the-shelf 2D Stable Diffusion models. An updated version of MVEdit has been merged into the 3D-Adapter project.
Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen,
Gordon Wetzstein
ECCV, 2024
GRM is a sparse-view feed-forward 3D Gaussian splatting reconstruction model with high efficiency (~0.1s). When combined with multi-view image diffusion, GRM can generate high-quality 3D objects from texts or images.
Minghua Liu*, Ruoxi Shi*, Linghao Chen*, Zhuoyang Zhang*, Chao Xu*, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, Hao Su
CVPR, 2024
Combining multiview diffusion and multiview-conditioned 3D diffusion models, One-2-3-45++ is capable of transforming a single RGB image of any object into a high-fidelity textured mesh in under one minute.

Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, Hao Su
Technical report, 2023
Zero123++ transforms a single RGB image of any object into high-quality multiview images with superior 3D consistency, serving as a strong base model for image-to-3D generative tasks.
Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, Hao Su
ICCV, 2023
With 3D diffusion models and NeRFs trained in a single stage, SSDNeRF learns powerful 3D generative prior from multi-view images, which can be exploited for unconditional generation and image-based 3D reconstruction.

Hansheng Chen, Pichao Wang, Fan Wang, Wei Tian, Lu Xiong, Hao Li
CVPR, 2022 (Best Student Paper)
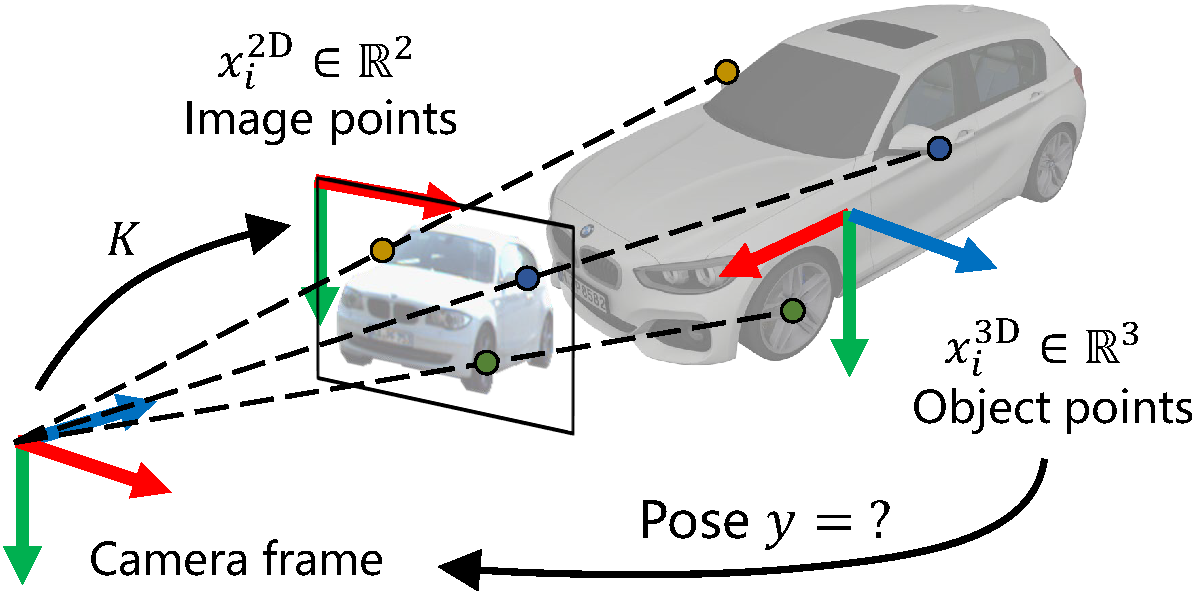
We present a probabilistic PnP layer for end-to-end 6DoF pose learning. The layer outputs the pose distribution with differentiable probability density, so that the 2D-3D correspondences can be learned flexibly by backpropagating the pose loss.
Hansheng Chen, Wei Tian, Pichao Wang, Fan Wang, Lu Xiong, Hao Li
TPAMI, 2024
The updated paper features improved models with better results on both the LineMOD and nuScenes benchmark. Morever, we have added more discussions on the loss functions, which are supported by rigorous ablation studies.
Hansheng Chen, Yuyao Huang, Wei Tian, Zhong Gao, Lu Xiong
CVPR, 2021
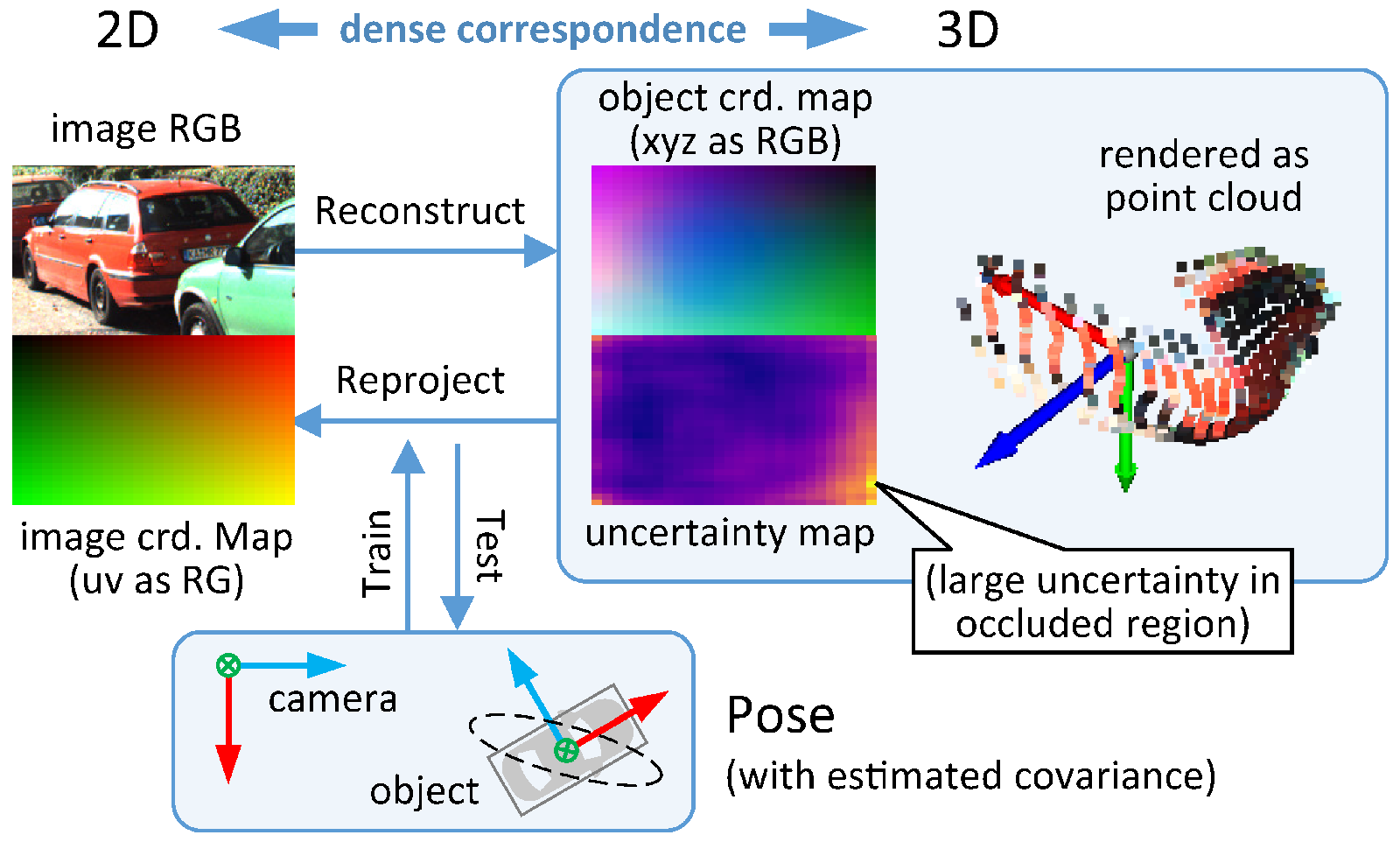
We present a novel 3D object detection framework based on dense 2D-3D correspondences. An uncertainty-aware reprojection loss is proposed to learn the 3D coordinates without prior knowledge of the object geometry.
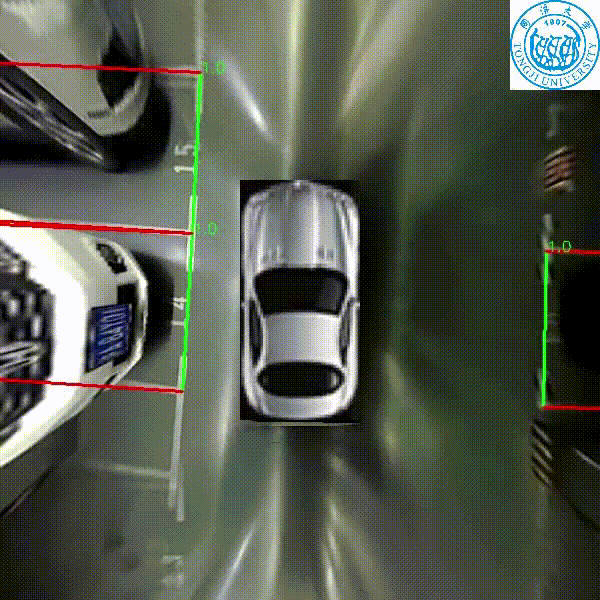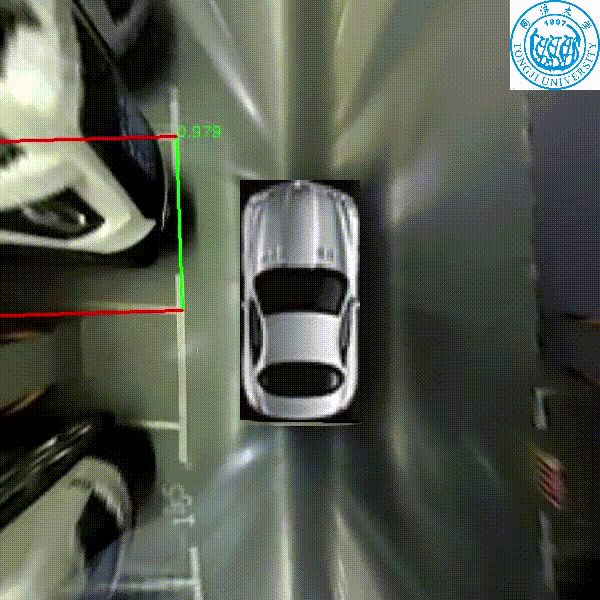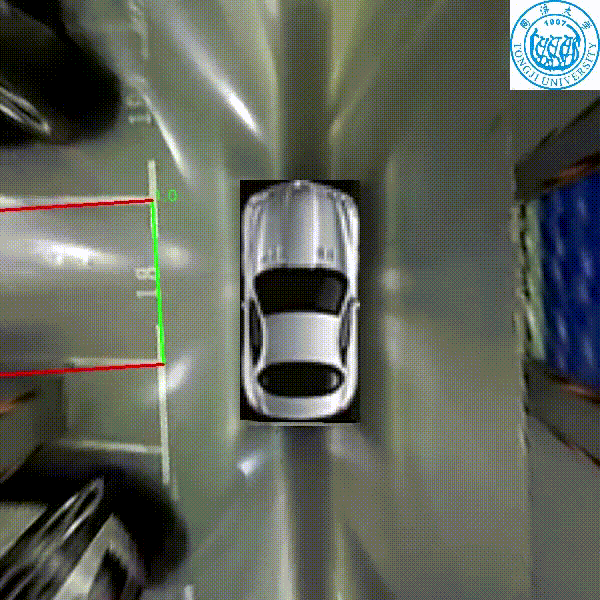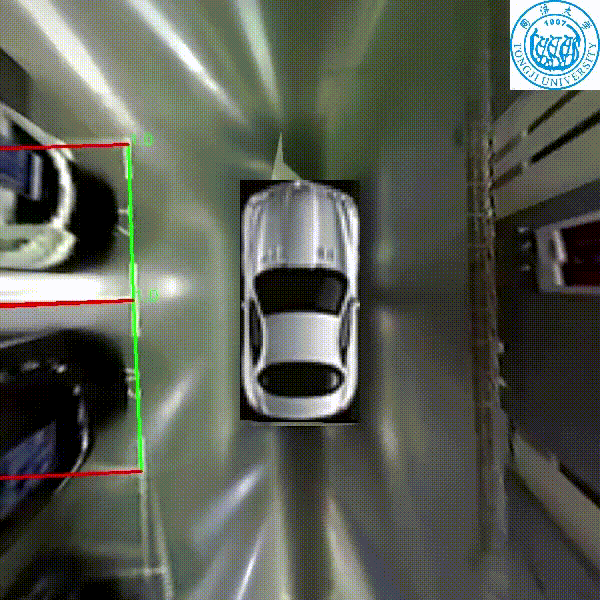
Zhuoping Yu, Zhong Gao, Hansheng Chen, Yuyao Huang
IEEE Intelligent Vehicles Symposium (IV), 2020
A real time parking slot detection model that runs 30 FPS on a 2.3 GHz CPU core, yielding corner localization error of 1.51±2.14 cm (std. err.) and slot detection accuracy of 98%.